
4.15 ATE: Average Treatment Effect A verage T reatement E ffect: The average difference in the pair of potential outcomes averaged over the entire population of interest (at a particular moment in time) ATE = E [Y i1 - Y i0]
Full Answer
How can I learn more about treatment effects in Stata?
· 08 Oct 2019, 02:51. Addendum: I have tested a number of different examples by now, so I can say with a certain confidence that the easiest way to get the Average Treatment Effect on the Untreated (ATU) is to type: estat teffects, atet subpop (if treatmentvariable ==0)
How do you estimate average treatment effects?
· The topic for today is the treatment-effects features in Stata. Treatment-effects estimators estimate the causal effect of a treatment on an outcome based on observational data. In today’s posting, we will discuss four treatment-effects estimators: RA: Regression adjustment. IPW: Inverse probability weighting.
What are Atet and poms in Stata?
· Without this, estimates of average treatment effects can be sensitive to the choice of, and small changes in the implementation of, the estimators. In this part of the analysis, the propensity score plays an important role. Second, it is useful to do some assessment of the appropriateness of the unconfoundedness assumption.
What is a treatment-effects estimator?
Average treatment e ect If we had data on each potential outcome, the sample-average treatment e ect would be the sample average of bw smoke minus bw nosmoke. mean bw_smoke bw_nosmoke Mean estimation Number of obs = 4642 Mean Std. Err. [95% Conf. Interval] bw_smoke 3171.72 .9088219 3169.938 3173.501 bw_nosmoke 3402.599 1.529189 3399.601 …
How do you calculate average treatment effect?
One common strategy for estimating average treatment effects is to leverage observed natural experiments, or natural processes which assign treatment to individuals in a way that is statistically independent from their potential outcomes.
How do you calculate average causal effect?
Using conditional expectations we have Average causal effect=E(Yi|Xi=1)−E(Yi|Xi=0), Average causal effect = E ( Y i | X i = 1 ) − E ( Y i | X i = 0 ) , where Xi is a binary treatment indicator.
What is average treatment effect on the treated?
The average treatment effect (ATE) is a measure used to compare treatments (or interventions) in randomized experiments, evaluation of policy interventions, and medical trials. The ATE measures the difference in mean (average) outcomes between units assigned to the treatment and units assigned to the control.
How do you analyze treatment effect?
The basic way to identify treatment effect is to compare the average difference between the treatment and control (i.e., untreated) groups. For this to work, the treatment should determine which potential response is realized, but should otherwise be unrelated to the potential responses.
What is the average causal effect?
In this article, the authors review Rubin's definition of an average causal effect (ACE) as the average difference between potential outcomes under different treatments. The authors distinguish an ACE and a regression coefficient.
What is conditional average treatment effect?
Abstract We consider a functional parameter called the conditional average treatment effect (CATE), designed to capture heterogeneity of a treatment effect across subpopulations when the unconfoundedness assumption applies.
How do you calculate AT&T?
Estimating the Average Treatment Effect for the Treated (ATT)Inverse probability weighting with ratio adjustment (IPWR). To estimate the ATT, the inverse probability weights that are described in the section Inverse Probability Weighting are multiplied by the predicted propensity scores. ... Regression adjustment (REGADJ).
Why are ATT and ATE different?
ATE is the average treatment effect, and ATT is the average treatment effect on the treated. The ATT is the effect of the treatment actually applied.
What is ATT in propensity score matching?
ATE: average treatment effect; ATT: average effect of the treatment on the treated; PS: propensity score.
What is treatment effect in statistics?
Treatment effects can be estimated using social experiments, regression models, matching estimators, and instrumental variables. A 'treatment effect' is the average causal effect of a binary (0–1) variable on an outcome variable of scientific or policy interest.
How do you find the treatment effect in RCT?
To estimate a treatment effect in an RCT, the analysis has to be adjusted for the baseline value of the outcome variable. A proper adjustment is not achieved by performing a regular repeated measures analysis (method 2) or by the regular analysis of changes (method 3).
What is the treatment effect in Anova?
The ANOVA Model. A treatment effect is the difference between the overall, grand mean, and the mean of a cell (treatment level). Error is the difference between a score and a cell (treatment level) mean.
What is the treatment effect manual in Stata?
An entire manual is devoted to the treatment-effects features in Stata 13, and it includes a basic introduction, advanced discussion, and worked examples. If you would like to learn more, you can download the [TE] Treatment-effects Reference Manual from the Stata website.
What is the treatment variable in Figure 1?
Figure 1 is a scatterplot of observational data similar to those used by Cattaneo (2010). The treatment variable is the mother’s smoking status during pregnancy, and the outcome is the birthweight of her baby.
Does treatment assignment depend on mother's age?
This figure shows that treatment assignment depends on mother’s age. We would like to have a method of adjusting for this dependence. In particular, we wish we had more upper-age green points and lower-age red points. If we did, the mean birthweight for each group would change. We don’t know how that would affect the difference in means, but we do know it would be a better estimate of the difference.
What is RA estimator?
RA estimators model the outcome to account for the nonrandom treatment assignment. Some researchers prefer to model the treatment assignment process and not specify a model for the outcome.
What is counterfactual outcome?
The counterfactual outcomes are called unobserved potential outcomes in the treatment-effects literature. Sometimes the word unobserved is dropped.
Is observational data unethical?
Experiments would be unethical. The problem with observational data is that the subjects choose whether to get the treatment. For example, a mother decides to smoke or not to smoke. The subjects are said to have self-selected into the treated and untreated groups.
What is a treatment?
A treatment could be a new drug and the outcome blood pressure or cholesterol levels. A treatment could be a surgical procedure and the outcome patient mobility. A treatment could be a job training program and the outcome employment or wages. A treatment could even be an ad campaign designed to increase the sales of a product.
Abstract
In this talk, I look at several methods for estimating average effects of a program, treatment, or regime, under unconfoundedness. The setting is one with a binary program.
Suggested Citation
Guido Imbens, 2007. " Estimating average treatment effects in Stata ," West Coast Stata Users' Group Meetings 2007 18, Stata Users Group.
Why do analysts randomly assign treatment?
In experimental studies, or studies where an analyst has control over treatment assignment, analysts can randomly assign treatment to individuals to ensure that the treatment and the potential outcomes of observed individuals are drawn from independent probability distributions. For example, if I were to assign email alerts with images to my email subscribers randomly, their potential outcomes from receiving emails with and without images, would be statistically independent from the event that they were chosen for treatment. While randomizing treatment enables the SDO to be an unbiased estimate of ATE, in order to minimize the variance of the estimate practitioners must also ensure they are calculating an SDO from a sufficiently large sample population.
Can we measure average treatment effects?
Unfortunately, as a result of the fundamental problem of causal inference, we cannot directly measure average treatment effects. This is because we cannot witness more than one potential outcome, as we cannot set an explanatory variable to more than one value.
Is SDO the same as ATE?
It is the intuitive estimation strategy you may be familiar with, simply the difference in means between treated and untreated individuals. Unfortunately, it is not exactly equivalent to the ATE. The SDO has two main sources of bias which can systematically distort the statistic away from the true value of an average treatment effect. The equation relating the SDO to the average treatment effect is as follows:
Is the ATT lower than the ATU?
In this example, the ATT is much lower than the ATU. The treatment effect on individuals who have been assigned treatment, which includes both economists, is (on average) less than the treatment effect on individuals who were not assigned treatment. We can calculate the ATT and the ATU as follows.
How many estimators are there for the average treatment effect?
Last time, we introduced four estimators for estimating the average treatment effect (ATE) from observational data. Each of these estimators has a different way of solving the missing-data problem that arises because we observe only the potential outcome for the treatment level received. Today, we introduce estimators for the ATE that solve the missing-data problem by matching.
When are IPW estimators not reliable?
The IPW estimators are not reliable when the estimated treatment probabilities get too close to 0 or 1.
When you have lots of continuous covariates, will NNM hinge on the bias adjustment?
When you have lots of continuous covariates, NNM will crucially hinge on the bias adjustment, and the computation gets to be extremely difficult.
How does NNM bias adjustment work?
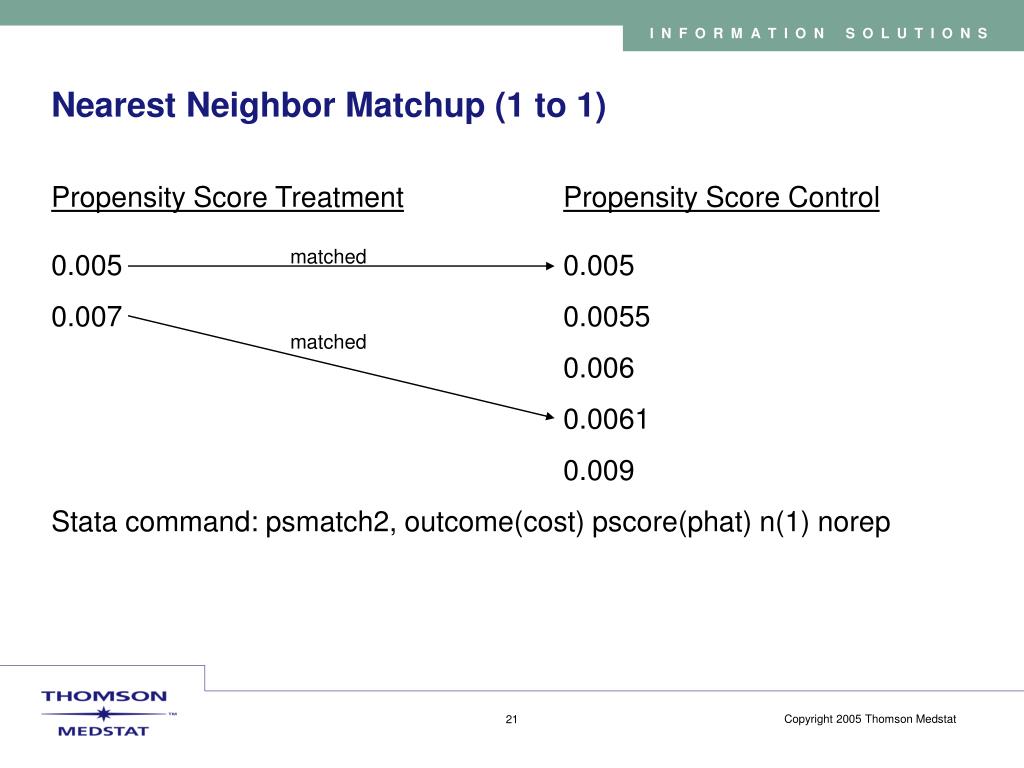
NNM uses bias adjustment to remove the bias caused by matching on more than one continuous covariate. The generality of this approach makes it very appealing, but it can be difficult to think about issues of fit and model specification. Propensity-score matching (PSM) matches on an estimated probability of treatment known as the propensity score. There is no need for bias adjustment because we match on only one continuous covariate. PSM has the added benefit that we can use all the standard methods for checking the fit of binary regression models prior to matching.
Can you use more than one continuous covariate?
Using more than one continuous covariate introduces large-sample bias, and we have three. The option biasadj () uses a linear model to remove the large-sample bias, as suggested by Abadie and Imbens (2006, 2011).
Why is dropping functional form assumptions important?
Dropping the functional-form assumptions makes the NNM estimator much more flexible; it estimates the ATE for a much wider class of models. The cost of this flexibility is that the NNM estimator requires much more data and the amount of data it needs grows with each additional continuous covariate.
When is matching used in experimental data?
Before we discuss estimators for observational data, we note that matching is sometimes used in experimental data to define pairs, with the treatment subsequently randomly assigned within each pair. This use of matching is related but distinct.
