Methods of treating missing values
- Ignoring and discarding data. There are two may of discarding or deletion of the missing values- List wise and Pairwise.
- Mean/ Median/ Mode Imputation. In these methods of imputation, the missing values are imputed by estimates such as mean,...
- Use of Prediction Models. This is where supervised modeling can be done to find the values...
Why is missing value treatment required before modeling data?
Missing value treatment is required on the data before it can be used for modeling as missing values in the data can reduce the power of the model and can make us draw wrong inferences from the model often leading to wrong predictions and classifications.
What is the best way to deal with missing values?
Deletion is the easiest way of treating missing values in a data set but not the best. The tendency to pick it as the first choice as a data analyst is very high.
What are the different types of missing values in statistics?
All the missing values can be broadly categorized into three types- MCAR, MAR and NMAR. MCAR: Missing completely at random is when the missing values are present randomly and missing values of a variable does not depend on either the known values or the missing data.
What are the different ways of discarding or deletion of missing values?
There are two may of discarding or deletion of the missing values- List wise and Pairwise. Listwise Deletion: It is the most simple way of treating a missing value where the records (rows) having missing values are removed from the dataset.

What do you mean by missing value treatment?
Missing values depend on the unobserved data. If there is some structure/pattern in missing data and other observed data can not explain it, then it is Missing Not At Random (MNAR). If the missing data does not fall under the MCAR or MAR then it can be categorized as MNAR.
What means missing value?
Missing data (or missing values) is defined as the data value that is not stored for a variable in the observation of interest. The problem of missing data is relatively common in almost all research and can have a significant effect on the conclusions that can be drawn from the data [1].
What are the options available for treatment of missing values?
There are various statistical methods like regression techniques, machine learning methods like SVM and/or data mining methods to impute such missing values.
How do you use missing value treatment in R?
There are really four ways you can handle missing values:Deleting the observations. ... Deleting the variable. ... Imputation with mean / median / mode. ... Prediction.4.1. ... 4.2 rpart. ... 4.3 mice.
How do you find missing values?
Find missing valuesGeneric formula. ... To identify values in one list that are missing in another list, you can use a simple formula based on the COUNTIF function with the IF function. ... The COUNTIF function counts cells that meet criteria, returning the number of occurrences found. ... Count missing values.More items...
How does SPSS treat missing values?
Cases with missing values are deleted listwise, i.e., observations with missing values on any of the variables in the analysis are omitted from the analysis. Cases with any missing value are excluded from any single complete ANOVA design in which the missing value is encountered.
What is the best imputation method?
To summarize, simple imputation methods, such as k-NN and random forest, often perform best, closely followed by the discriminative DL approach. However, for imputing categorical columns with MNAR missing values, mean/mode imputation often performs well, especially for high fractions of missing values.
Why is it important to understand how do you manage missing values?
The concept of missing values is important to understand in order to successfully manage data. If the missing values are not handled properly by the researcher, then he/she may end up drawing an inaccurate inference about the data.
How do you define missing values in R?
In R, missing values are represented by the symbol NA (not available). Impossible values (e.g., dividing by zero) are represented by the symbol NaN (not a number). Unlike SAS, R uses the same symbol for character and numeric data.
How missing values are represented in R?
In R, missing values are represented by the symbol NA (not available). Impossible values (domain errors like division by 0 et logs of negative numbers are represented by the symbol NaN (Not-A-Number). NA is used for both numeric and string data.
How do I find missing values in a column in R?
In R, the easiest way to find columns that contain missing values is by combining the power of the functions is.na() and colSums(). First, you check and count the number of NA's per column. Then, you use a function such as names() or colnames() to return the names of the columns with at least one missing value.
What to replace missing values with?
Replace missing values with mean, median and mode OR consider missing values as a different category
What happens if you miss a value?
Missing values if not properly interpreted can lead to poor decisions which can lead to sever loss of business. For example if ‘Marital Status’ is very important for sending a personalized communication to the customers and let us assume for 20% of the records Marital Status is not available, either we don’t target these customers or we try to predict the value of this variable. If the prediction method is not good enough then we might end up sending incorrect communication to the customers. So its interpretation is really important if the decisions are to work as expected.
What happens when you drop a record with one missing value?
This might lead to significant Information loss of 21.7%.
What does "remove records with at least one missing value" mean?
Removing records with at least one missing value: It simply means removing all the records that have at least one missing value.
How much information loss is there when you remove columns that are of least significance?
By removing columns which are of least significance, number of records is reduced by 17% (from 614 to 505). So Information loss is 17%. Although not the best way to treat missing values, but better than the first one.
Can missing values be replaced by median and mode?
Similarly we can replace missing values by Median and Mode.
Is data unavailability a problem?
Data unavailability is not always a problem. There are fields in an application form or surveys that are not mandatory. Organizations feel the field or the attribute will not add much value and can be ignored. This hypothesis can easily be verified by checking the trend of this variable (with available data) with required outcome. If there is no trend then data unavailability for such variables is not really a problem. But if any trend is seen, then business should take a wise decision of making it as a mandatory field and start collecting it.
What is the most advanced method to impute your missing values?
Prediction is most advanced method to impute your missing values and includes different approaches such as: kNN Imputation, rpart, and mice.
How many ways can you handle missing values?
There are really four ways you can handle missing values:
What is the limitation of DMWR::knnImputation?
The limitation with DMwR::knnImputation is that it sometimes may not be appropriate to use when the missing value comes from a factor variable. Both rpart and mice has flexibility to handle that scenario. The advantage with rpart is that you just need only one of the variables to be non NA in the predictor fields.
Why remove a variable?
If a particular variable is having more missing values that rest of the variables in the dataset, and, if by removing that one variable you can save many observations. I would, then, suggest to remove that particular variable, unless it is a really important predictor that makes a lot of business sense. It is a matter of deciding between the importance of the variable and losing out on a number of observations.
Is there enough evidence to conclude which method is better or worse?
Though we have an idea of how each method performs, there is not enough evidence to conclude which method is better or worse. But these are definitely worth testing out the next time you impute missing values.
Can you impute all missing values in a function?
The advantage is that you could impute all the missing values in all variables with one call to the function. It takes the whole data frame as the argument and you don’t even have to specify which variable you want to impute. But be cautious not to include the response variable while imputing, because, when imputing in test/production environment, if your data contains missing values, you won’t be able to use the unknown response variable at that time.
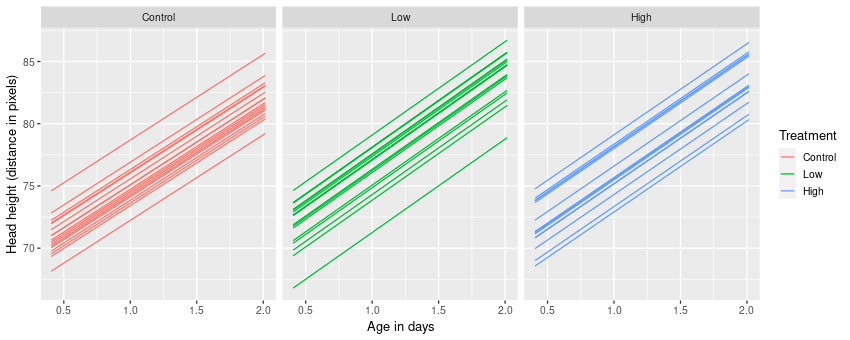
Revenue Prediction
We will be using a linear regression model to predict ‘Revenue’. A quick intuitive recap of Linear Regression Assume ‘y’ depends on ‘x’. We can explore their relationship graphically as below:
Missing Value Treatment
Let’s now deal with the missing data using techniques mentioned below and then predict ‘Revenue’.
Linear Regression Model Evaluation
A common and quick way to evaluate how well a linear regression model fits the data is the coefficient of determination or R 2.
Model Comparison post-treatment of Missing Values
Let’s compare the linear regression output after imputing missing values from the methods discussed above:
Conclusion
Imputation of missing values is a tricky subject and unless the missing data is not observed completely at random, imputing such missing values by a Predictive Model is highly desirable since it can lead to better insights and overall increase in performance of your predictive models.
How to treat missing values?
We generally have three options when it comes to dealing with missing values.
What happens if the total number of observations with missing values is not significant?
2. If the total number of observations with missing values is not significant, then we can delete all such representations.
What is missing data?
Missing data is a common phenomenon which you will notice while working on datasets. Presence of missing values has a significant effect on the conclusions. Therefore, it becomes essential to understand and learn how to deal with variables/observations which have missing values. There are many ways in which you can deal with missing values, and in this post, we will look at all of them. We will also see how a data scientist will typically approach a dataset when he has a focus on figuring out and treating missing values.
Which package has very generic functions which makes it easy to impute values?
3. Hmisc – The package has very generic functions which makes it easy to impute values. Read here to know more about these functions.
Can we delete variables?
Removing an entire variable means loss of information and thus can be tricky at times. By the rule of thumb, we shall only delete the variables if the variable has more than 30% missing values.
Introduction
The task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some sense) to each other than to those in other groups (clusters). It is a common statistical techniques used in statistical analysis and EDA.
Dataset and Features
The Iris flower data set is a multivariate data set introduced by the British statistician and biologist Ronald Fisher in his 1936 paper The use of multiple measurements in taxonomic problems.
Benchmark Index
To set an initial benchmark, we will use KMeans with n_cluster=3 (3 species in the target class).
Masking
Data masking or data obfuscation is the process of hiding original data with modified content (characters or other data.). In our case the values are replaced with null
Single Column Missing Value Treatment
In this case, we are considering the scenario that there are missing values in a single column.
Multi Column Missing Value Treatment
In this case, we are considering the scenario that there are missing values across multiple columns.
Row Based Ignore
Steps are similar to Single Column Row Based Ignore, the only change is multiple columns are ignored for clustering instead of a single one. (Consider PL and PW columns have missing values)
Why is it important to treat missing values?
In conclusion, the treatment of missing values is very critical when doing data exploration and preparation. You need due diligence so as to have clean data that you can use to create better predictive models. The choice of the method depends on a number of factors.
Why do we treat missing values in datasets?
This can reduce the power of your model, lead to wrong prediction or classification because of the inability to analyze the behavior and relationship with other variables correctly in your dataset. In this article, I have briefly explored 4 methods that you can use to treat missing values in your dataset.
What is deletion in data analysis?
Deletion is the most common and easy way of treating missing values in a data set. The tendency to pick it as the first choice as a data analyst is very high. Let us see what happens here. First and foremost, there are 2 types of deletion i.e. listwise deletion and pairwise deletion.
How to replace missing values in KNN?
The values used to replace the missing values are obtained by using similarity-based distance metrics. The advantage of KNN imputation is that it is able to predict both discrete and continuous attributes in a data set.
What is Listwise deletion?
In Listwise deletion, all the observations where a variable is missing are deleted. It basically means deleting an entire row of variables. The disadvantage of this type of deletion is that it reduces that sample size and hence interferes with the accuracy of the model.
Is mean imputation specialized?
Mean/Median/Mode imputation can be generalized or specialized (similar case).
Is deletion the best method for treating missing values?
In as much as deletion is simple and convenient, it is not the best method for treating missing values for your data.
How to deal with missing values?
Dealing with Missing values 1 Valid data points get deleted. 2 This method relies on randomness 3 Reduces information
How to replace missing values in a numeric column?
We can replace missing values in a numeric column by using the measure of central tendency

mean/ Median/ Mode Imputation
- In these methods of imputation, the missing values are imputed by estimates such as mean, median or mode. Missing data can be replaced by mean or median for numerical variables while mode can be used to impute missing in categorical variables. For example, if we have a dataset …
Use of Prediction Models
- This is where supervised modeling can be done to find the values which can be used for imputing missing values. Here we divide our dataset into train and test with train having no missing values and test only having missing values. The training dataset can be used to train our model to predict the missing values for the target variable and this model can be used to find the missing values i…
K-Nearest Neighbour as An Imputation Method
- KNN is discussed in detail in the section Supervised Modeling. K-nearest Neighbour algorithm can be used to estimate and substitute missing data. Here the missing values are found by calculating the observations that are closest to it which is based on other features. For example, we have a dataset where we have we have three variables- Income, Age, Number of Cars Owned. We have …
Data Prep and Pattern
Deleting The Observations
- If you have large number of observations in your dataset, where all the classes to be predicted are sufficiently represented in the training data, then try deleting (or not to include missing values while model building, for example by setting na.action=na.omit) those observations (rows) that contain missing values. Make sure after deleting the observations, you have: 1. Have sufficent d…
Deleting The Variable
- If a particular variable is having more missing values that rest of the variables in the dataset, and, if by removing that one variable you can save many observations. I would, then, suggest to remove that particular variable, unless it is a really important predictor that makes a lot of business sense. It is a matter of deciding between the importance of the variable and losing out …
Imputation with Mean / Median / Mode
- Replacing the missing values with the mean / median / mode is a crude way of treating missing values. Depending on the context, like if the variation is low or if the variable has low leverage over the response, such a rough approximation is acceptable and could possibly give satisfactory results. Lets compute the accuracy when it is imputed with m...
Prediction
- Prediction is most advanced method to impute your missing values and includes different approaches such as: kNN Imputation, rpart, and mice.
Revenue Prediction
- We will be using a linear regression model to predict ‘Revenue’. A quick intuitive recap of Linear RegressionAssume ‘y’ depends on ‘x’. We can explore their relationship graphically as below:
Missing Value Treatment
- Let’s now deal with the missing data using techniques mentioned below and then predict ‘Revenue’. A. Deletion Steps Involved: i) Delete Delete or ignore the observations that are missing and build the predictive model on the remaining data. In the above example, we shall ignore the missing observations totalling 7200 data points for the 2 variables...
Linear Regression Model Evaluation
- A common and quick way to evaluate how well a linear regression model fits the data is the coefficient of determination or R2. 1. R2 indicates the sensitivity of the predicted response variable with the observed response or dependent variable (Movement of Predicted with Observed). 2. The range of R2is between 0 and 1. R2 will remain constant or keep on increasing …
Model Comparison Post-Treatment of Missing Values
- Let’s compare the linear regression output after imputing missing values from the methods discussed above: In the above table, the Adjusted R2 is same as R2since the variables that do not contribute to the fit of the model haven’t been taken into consideration to build the final model. Inference: 1. It can be observed that ‘Deletion’ is the worst performing method and the best one i…
Conclusion
- Imputation of missing values is a tricky subject and unless the missing data is not observed completely at random, imputing such missing values by a Predictive Model is highly desirable since it can lead to better insights and overall increase in performance of your predictive models. Source Code and Dataset to reproduce the above illustration available here This blog originally a…